

Сегодня мне впервые не повезло. Я наткнулся на источник данных, который не хотел обновляться больше, чем за 5 дней. Это был Calltouch крупного клиента, а именно таблица заявок.
Когда я пытался забрать статистику за 5 дней с помощью своего коннектора в Power Query - всё было хорошо. Но стоило запросить 10 дней - Calltouch выдавал 500-ю ошибку.
Я уже собирался создавать таблицу в базе данных и писать на python скрипт, который ежедневно будет закачивать данные из Calltouch. Это было бы долго, так как отчёт по заявкам выдаётся в нестандартном формате.
Потребовалось бы создать таблицу в базе с правильными типами данных, корректно загрузить все данные и запустить у себя на компьютере ежедневное обновление. Дело не быстрое, а ошибок наделать легко.
Но вдруг вспомнил про метод Максима Зеленского, который предлагал делать инкрементное обновление потоков данных (жмите на ссылку колёсиком мыши).
Такой метод мне казался немного сложным и что хуже - неуправляемым. Ведь стоило неудачно обновиться - и казалось, что весь процесс нужно выстраивать заново. Но когда я немного переосмыслил метод, всё встало на свои места.
Метод сегментов по N дней
Если вкратце, метод основан на том, что из потока данных мы обращаемся к этому же потоку, при этом дополняя его новыми данными. Каждый день наш поток пополняется свежими данными, при этом не теряя исторических данных, что довольно удобно.
Всё, что нужно - сделать управляемым исправление ошибок при подтягивании данных. А на практике ошибки случаются довольно часто.
Итак, нам понадобится 5 запросов:
- Запрос к обновляемому сегменту (у меня это запрос Заявки1)
- Запрос к сохранённым данным в этом же потоке (Поток)
- Дата начала (или окончания) получения свежей статистики
- Функция, которая забирает данные из источника (в моём случае из Calltouch)
- Запрос, где я отслеживаю наличие загруженных в поток дат (Все даты потока)

Помимо этого, мы должны выбрать количество дней, которое мы будем обновлять.
В моём случае будет 4 дня - чтобы уж наверняка.
В первом запросе - к обновляемому сегменту - я указываю период с "Даты начала" до "Дата начала + 3 дня":

Если удобнее оперировать датой окончания, то с "Даты окончания минус 3 дня" до "Даты окончания". Главная идея в том, что свежий период зависит от одной даты и имеет стандартный размер в днях.
Во втором запросе - к сохранённым данным в потоке - мы убираем указанный период из статистики:

То есть принудительно вырезаем все 4 дня, которые есть в свежем запросе. И опять запрос зависит от одной единственной даты - ДатаНачала.
Получается 2 непересекающиеся запроса: один - только что полученные данные, а второй - весь остальной объем данных. И оба этих запроса зависят от параметра ДатаНачала.
Результатом потока должно быть объединение двух запросов - свежей и исторической статистики. Я просто добавил к результату обновляемого периода результат исторических данных потока. Этот запрос и выгружается как результат потока (запрос Заявки1).
Чтобы данные сохранились в потоке, он должен обновиться. Я начал с даты, которая была 4 дня назад, загрузив в поток последние дни.
Проверить какие данные есть в потоке можно изнутри - для этого я создал запрос "Все даты потока". Он, как и запрос "Поток", подключается к данным этого же потока, но в нём нет фильтра. В нём и находятся все даты нашего потока, пока что их всего 4:
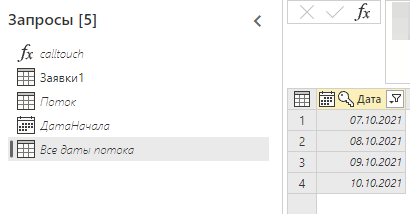
Этот запрос еще пригодится нам для проверки загружаемых дат.
И что же дальше? Каковы преимущества метода?
При нашей возможности менять ДатуНачала, статистика обновляемого сегмента не обязательно должна быть свежей. Точнее, она может быть совсем несвежей!
Анонсы всех видео, статей и полезностей - в нашем Telegram-канале🔥
Присоединяйтесь, обсуждайте и автоматизируйте!
Например, теперь мы можем сдвигаться по 4 дня в прошлое и шаг за шагом собирать старые данные. Каждый раз устанавливаем дату начала/окончания на 4 дня раньше и собираем недостающий кусок, обновляя наш поток:
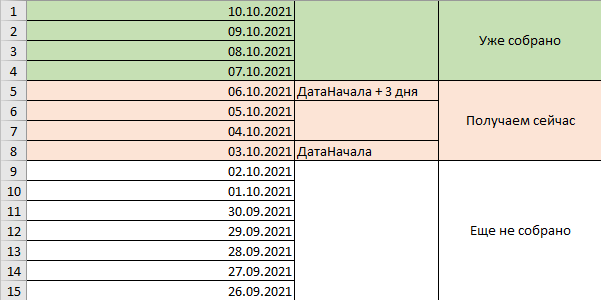
Вы можете работать и с бОльшим количеством дат если объемы данных это позволяют. Можно взять не 4 дня, а 30. Для многих источников это приемлемый объем. При этом можно быть уверенным, что ничего не сломается, поскольку периоды в историческом и свежем запросах никогда не пересекутся. Главное - не пропускать каких-то дат, чтобы данные были полными.
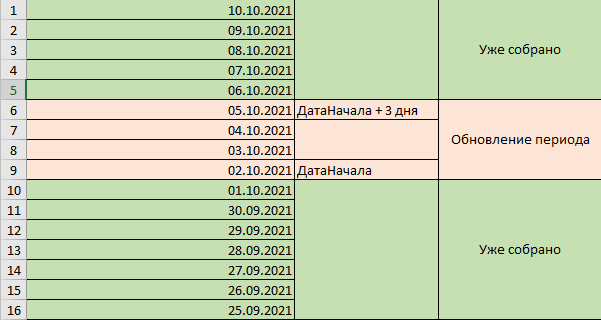
Но даже если пропустите - не страшно. Всегда можно вернуться и пересобрать нужный сегмент. Я думаю в этом и есть главное преимущество сегментов по N дней. Поток превращается в управляемую базу данных, где всегда можно скорректировать что-то, переместив дату в нужное место и обновив поток:
Когда все исторические данные собраны, а ошибки исправлены, возвращаемся к последним датам и переводим дату начала/окончания в динамический формат. Например, я ставлю дату начала на 4 дня назад от сегодняшнего дня:
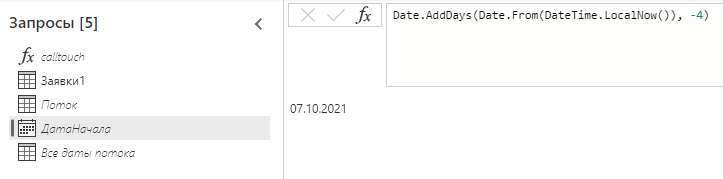
Теперь каждый день я буду перезаписывать 4 последних дня. А если найду ошибку - вернусь назад и обновлю любой желаемый период. По-моему круто;)
Подведём итоги
Какие плюсы мы получили?
- Собрали большой пласт исторической статистики, который было сложно собрать по-другому. Можно конечно скачать файл, но там немного другая структура и столбцы, да и зачем;)
- При обновлении мы получаем только небольшой период, поэтому: а) поток обновляется очень быстро, б) конструкция надёжна и не сломается через неделю от накопления данных.
- Если возникает ошибка - можно сместить дату назад и пересобрать исторические данные. При этом ничего не сломается. Главное - не забыть вернуть дату на последние дни.
- Управляем сбором с помощью единственного параметра - даты начала/окончания, что очень удобно.
Метод Максима Зеленского по инкрементному обновлению потоков данных отлично работает. Но для гибкого управления периодом нужен соответствующий параметр управляющей даты и небольшие коррективы по фильтрации дат.
Что самое приятное - имея возможность получать данные хотя бы за несколько дней, теперь мы можем собирать данные за несколько лет. Всего то нужна версия Power BI Pro, коннектор к вашему источнику данных и немного терпения;)






Комментарии