

Приветствую всех, кто интересуется ИИ. ChatGPT - это круто, но он не всегда нам подходит: сложный процесс регистрации из РФ, обязательный VPN, подписка Plus за 20$, а также большой расход на API могут вас отпугнуть. Всё это осложняется тем, что модели OpenAI закрыты - их никто не выложит в интернет и работать с ними бесплатно не получится.
Но вы наверняка слышали, что в интернете полно других LLM (больших языковых моделей). Многие из них - opensource, то есть изначально делались открытыми. С подобными моделями можно работать локально, загрузив их себе на компьютер. На это не нужно больших расходов - только хороший компьютер (или же сервер) и желание тестировать:)
Сегодня попробуем выбрать некоторые LLM - аналоги ChatGPT - и запустить их у себя на компьютере. И для этого будем использовать программу под названием LM Studio.
Интерфейс LMstudio
LM Studio - это инструмент, позволяющий работать с различными ИИ-моделями. Найдите на сайте https://lmstudio.ai/ подходящую версию программы для вашей ОС, скачайте и установите её. Процесс установки стандартный, не отличается от большинства других программ.
У LM Studio удобный интерфейс с поиском по LLM. Вы можете искать популярные opensource-модели, такие как LLaMa или Mistral:
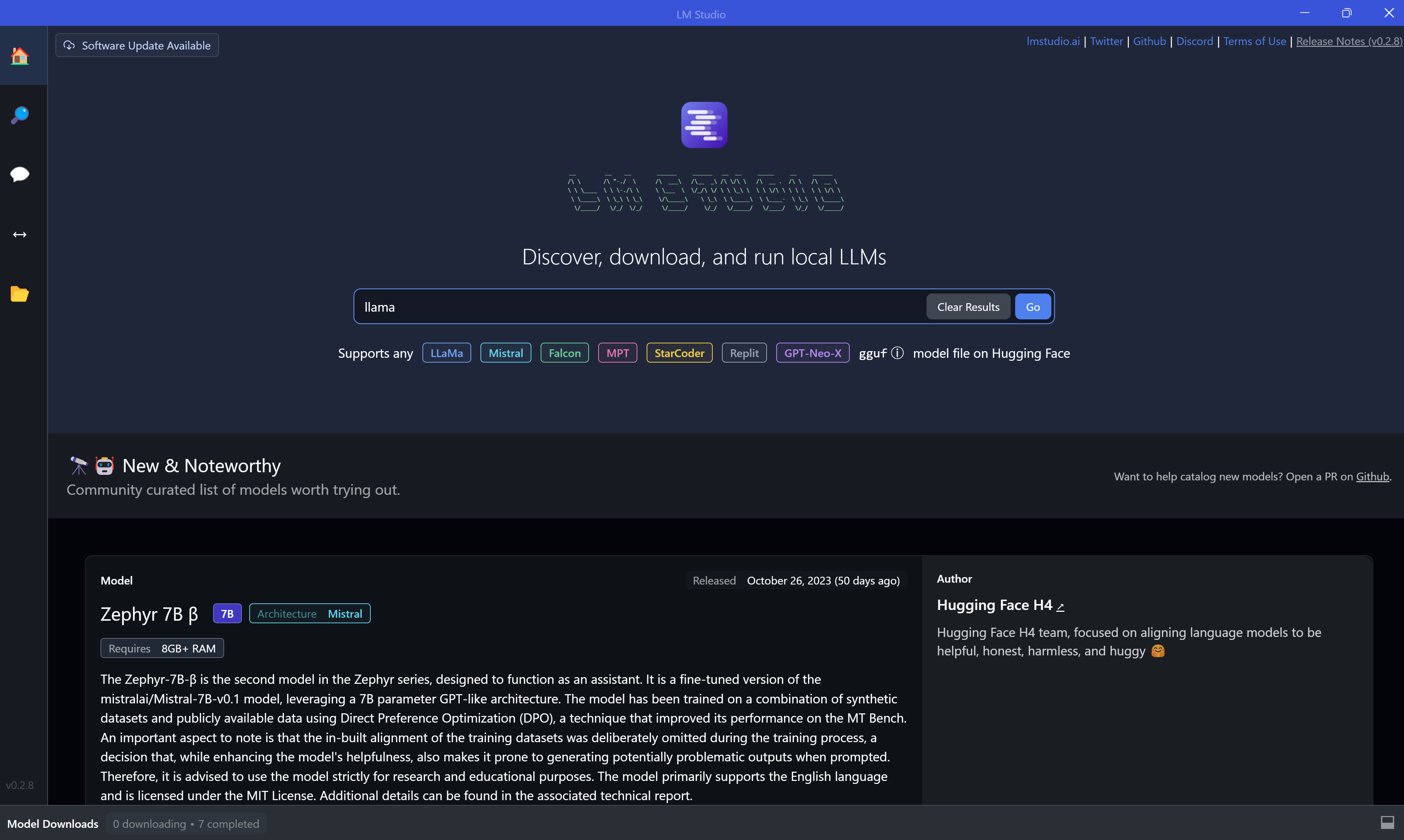
При нажатии на поиск вас перекинет во второе окно, где система представит на выбор ряд моделей. Если вы видите сверху кнопку "compatibility guess", то вам показаны далеко не все модели, соответствующие запросу. Вы видите только те модели, которые могут корректно работать на вашей машине. Чтобы увидеть все модели, нажмите на эту кнопку и с небольшой задержкой она сменится на "all models" - вот теперь вы видите всё.
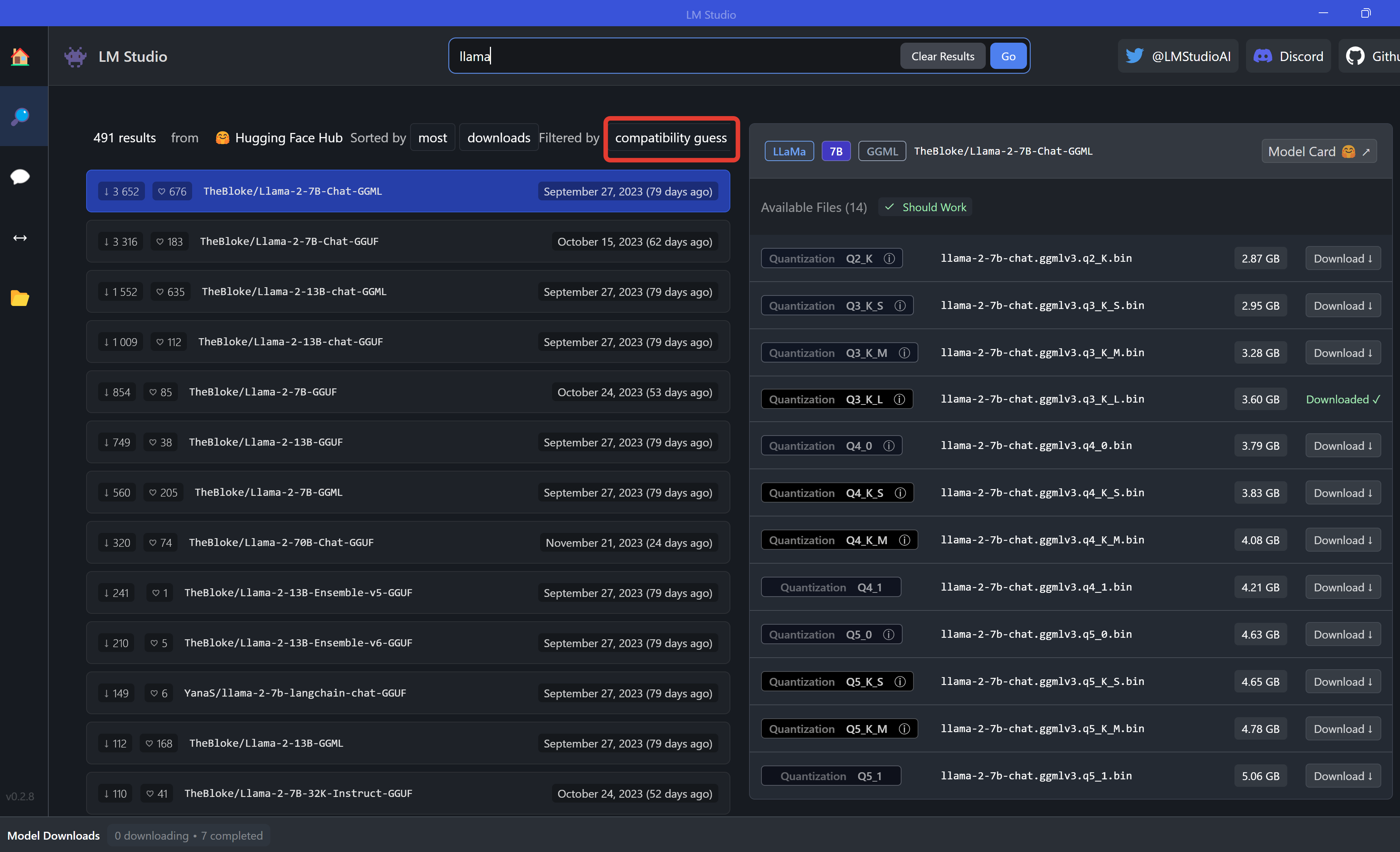
При выборе конкретной модели справа отображаются её вариации, имеющие разный вес. Дело в том, что на вашем компьютере вы не запустите огромную модель, поэтому её немного урезают с помощью квантования. По итогу вы можете видеть справа версии от Q2 (с минимальным качеством ответов и минимальным весом) до Q8 (с более точными ответами и бОльшим весом). Проблема в том, что более точные ответы требуют гораздо больше времени, так как сильно нагружают машину.
Анонсы всех видео, статей и полезностей - в нашем Telegram-канале🔥
Присоединяйтесь, обсуждайте и автоматизируйте!
Нажмите на Download справа от выбранной версии и внизу появится полоса загрузки моделей. Загрузите модели на ваш компьютер перед использованием.
В третьем окне можно найти что-то типа ChatGPT - тут можно создавать чаты, общаться с моделью, а справа - задавать настройки:
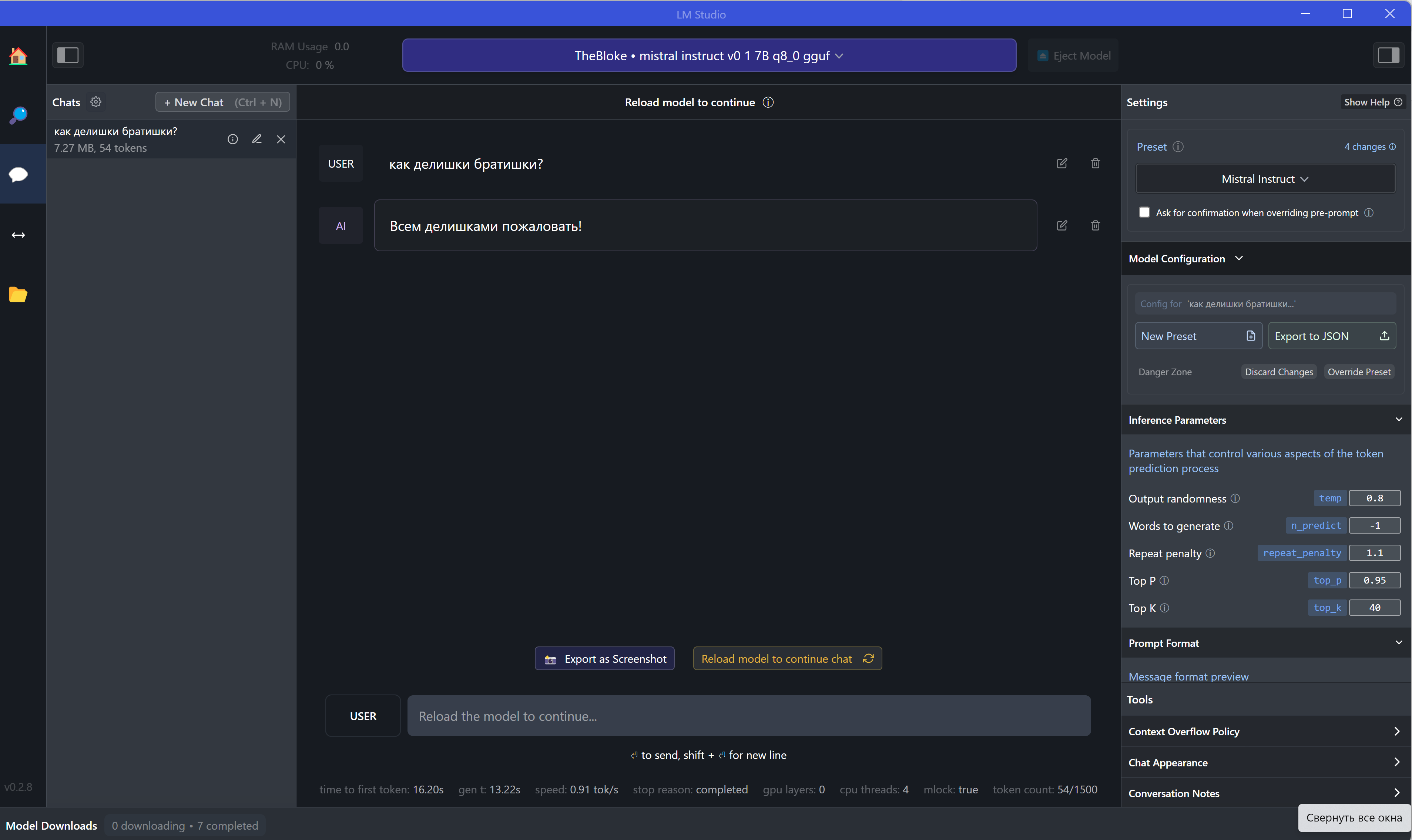
Но было бы странно ставить LM Studio, чтобы просто пообщаться с моделью - ведь для этого есть ChatGPT, Bard, GigaChat и другие ИИ. Основная проблема - автоматизация процессов. Общение по API требует расходов, ведь как правило именно за API берут деньги компании типа OpenAI.
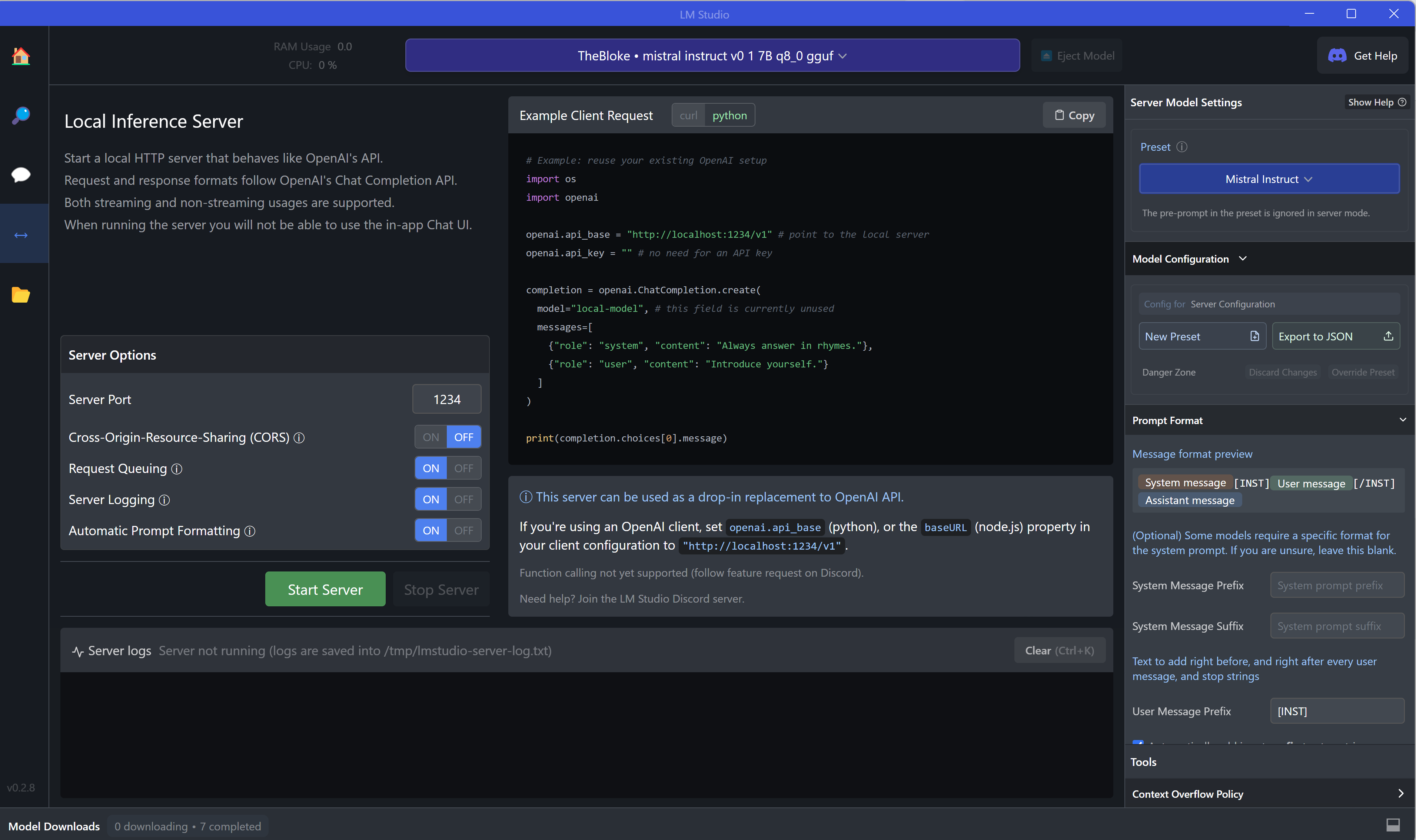
Поэтому в четвёртом окне программы есть возможность запустить локальный сервер с выбранной моделью, чтобы вести с ним диалог программно. Это даёт массу возможностей автоматизации и позволяет проектировать ИИ-помощников даже без интернета, надо только запустить сервер зелёной кнопкой.
Ну и конечно набор моделей, которые вы скачали и можете использовать - пятое окно интерфейса. Непонравившиеся можно удалить.
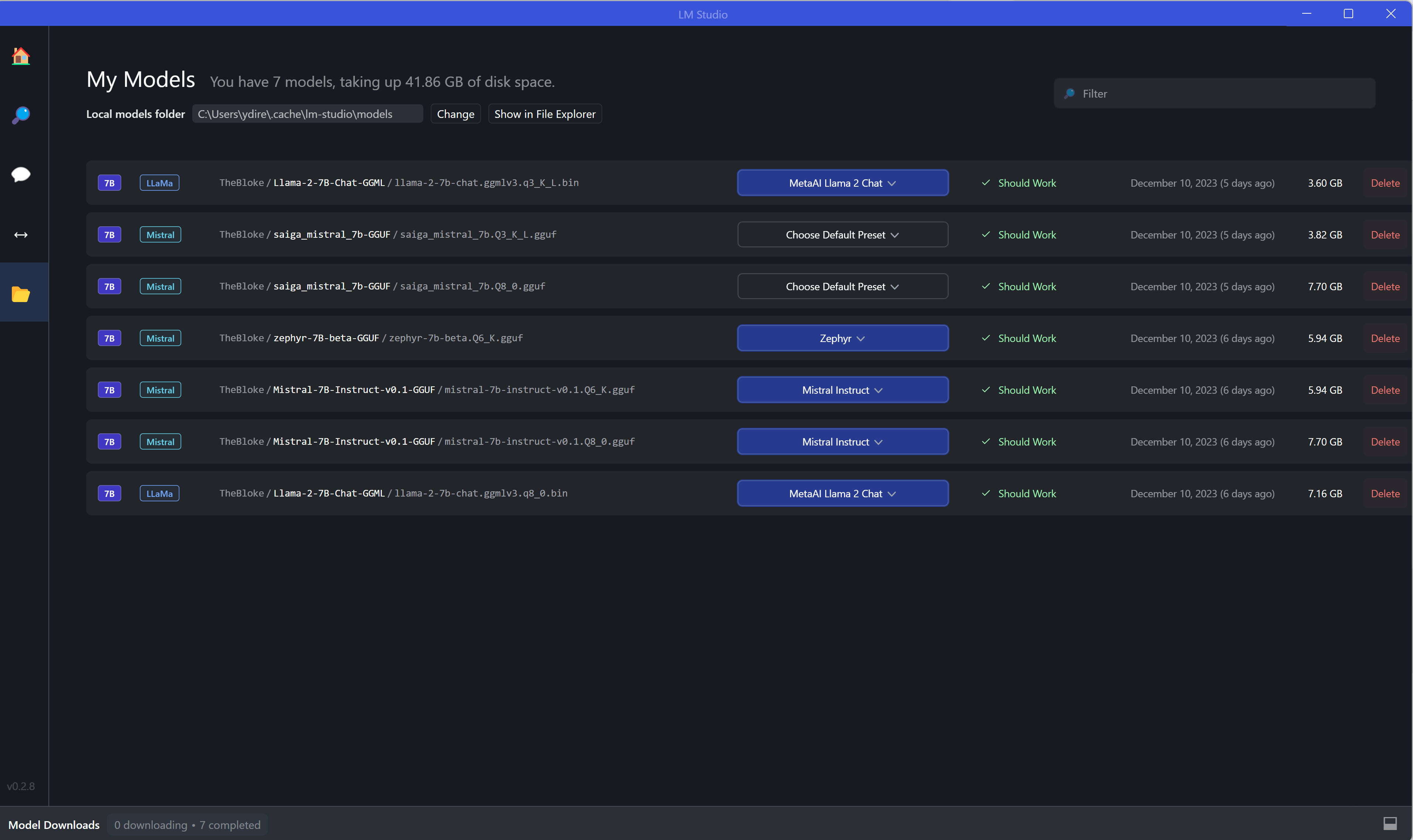
В целом интерфейс у программы простой, даже неподготовленному пользователю будет не так сложно в нём разобраться.
У локальных LLM 3 проблемы
В качестве теста я решил взять Saiga Mistral, LLaMa 2 7B Chat и Mistral 7B Instruct - это то, что может работать на моем компьютере.
Проблема 1 - слабые тексты
Сперва попробуем русскоязычную Saiga Mistral с квантованием Q2 - самую лёгкую и быструю.

Локальные модели часто пишут по смыслу и даже неплохо, но их формулировки типа "занятие наших курсов" не позволяют полноценно их использовать без постоянных исправлений.
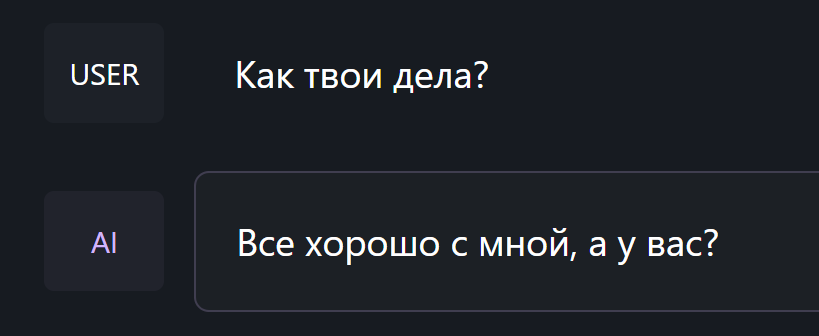
Видя подобные ляпы сразу хочется закрыть Saiga Mistral вернуться к ChatGPT. Но возможно я просто открыл слишком урезанную версию (всего 3ГБ).
Проблема 2 - скорость
Давайте попробуем модель побольше - например Mistral 7B Instruct с Quantization Q8.
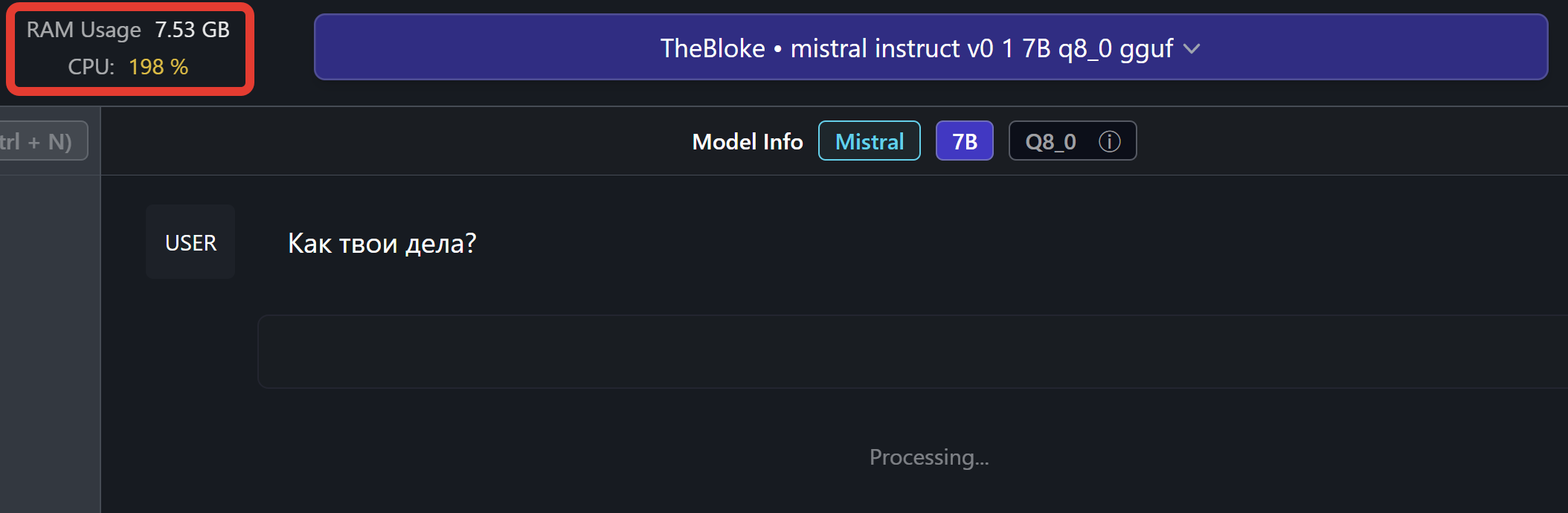
Тут возникает другая проблема - даже если модель подходит под вашу машину, никто не сказал, что она будет быстро работать. Как итог - сильная загрузка процессора, долгий подбор ответа и некоторое зависание компьютера. И даже если подобная модель начинает писать текст, она делает это крайне медленно, параллельно мешая другим процессам на вашей машине.
Проблема 3 - язык
Теперь попробуем всем известную LLaMa, а точнее LLaMa 2 7B Chat. На этот раз взял Q3, чтобы избежать зависаний.
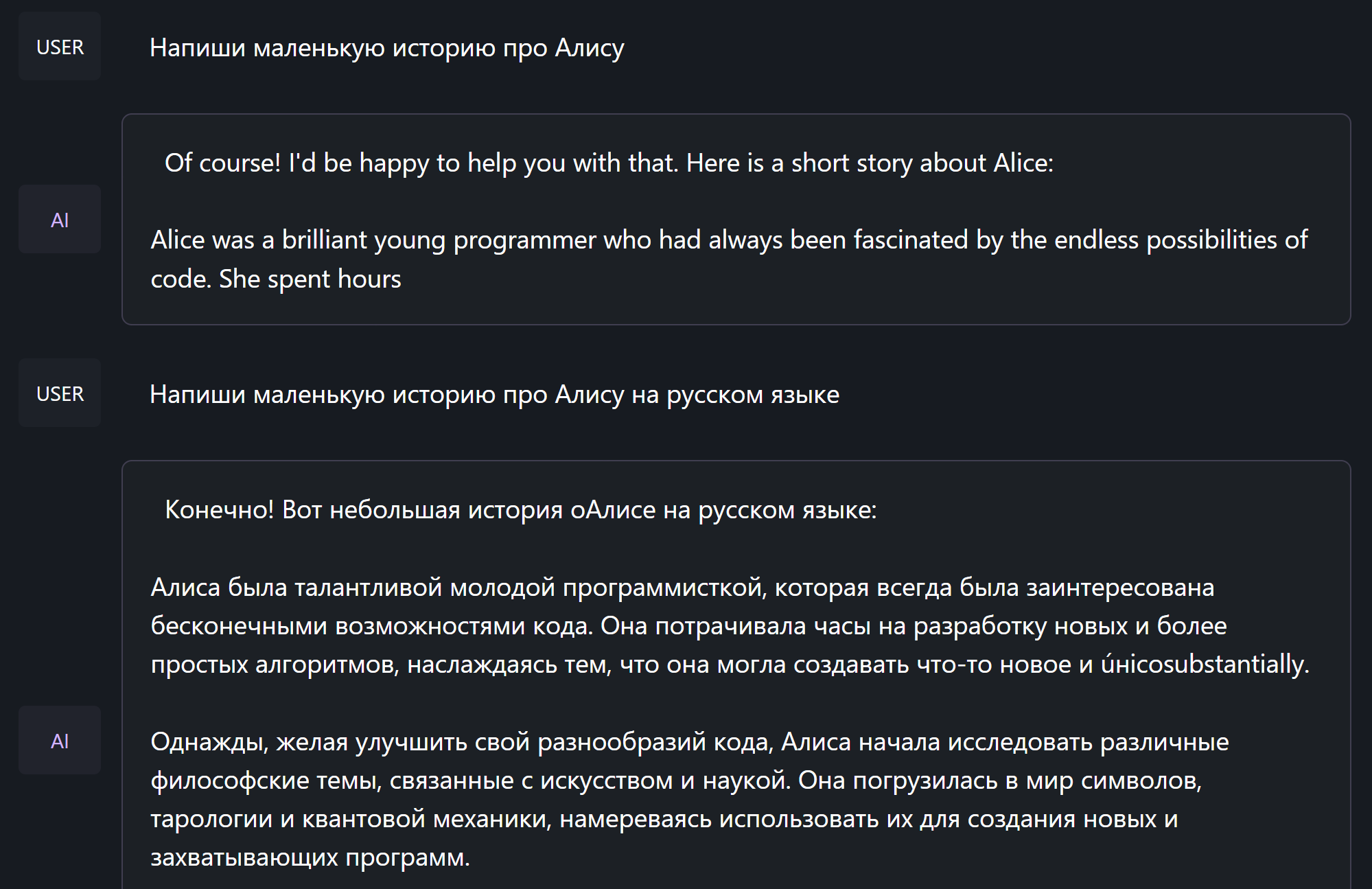
Минус LLaMa - заточенность под английский язык. На русском она пишет с трудом, а порой просто игнорирует прямое указание писать на русском и снова переходит на родной язык. Поэтому постоянные правки русскоязычных текстов обеспечены, если конечно повезёт и они вообще будут на русском.
Запуск сервера в LMstudio
Теперь попробуем писать программы. Для этого нам нужно развернуть локальный сервер - жмём на зелёную кнопку:
Для обращения к нашему серверу на Python я не пользовался стандартным кодом, а написал свой запрос. Во первых, мне нужно было нормально читать русский язык, а во вторых - реализовать ожидание ответа в случае долгой генерации.
Для выставления ожидания ответа я использовал timeout, а для обработки русского языка - стандартную кодировку utf-8. Запрос делается по локальной ссылке без подключения к интернету, в остальном всё стандартно.
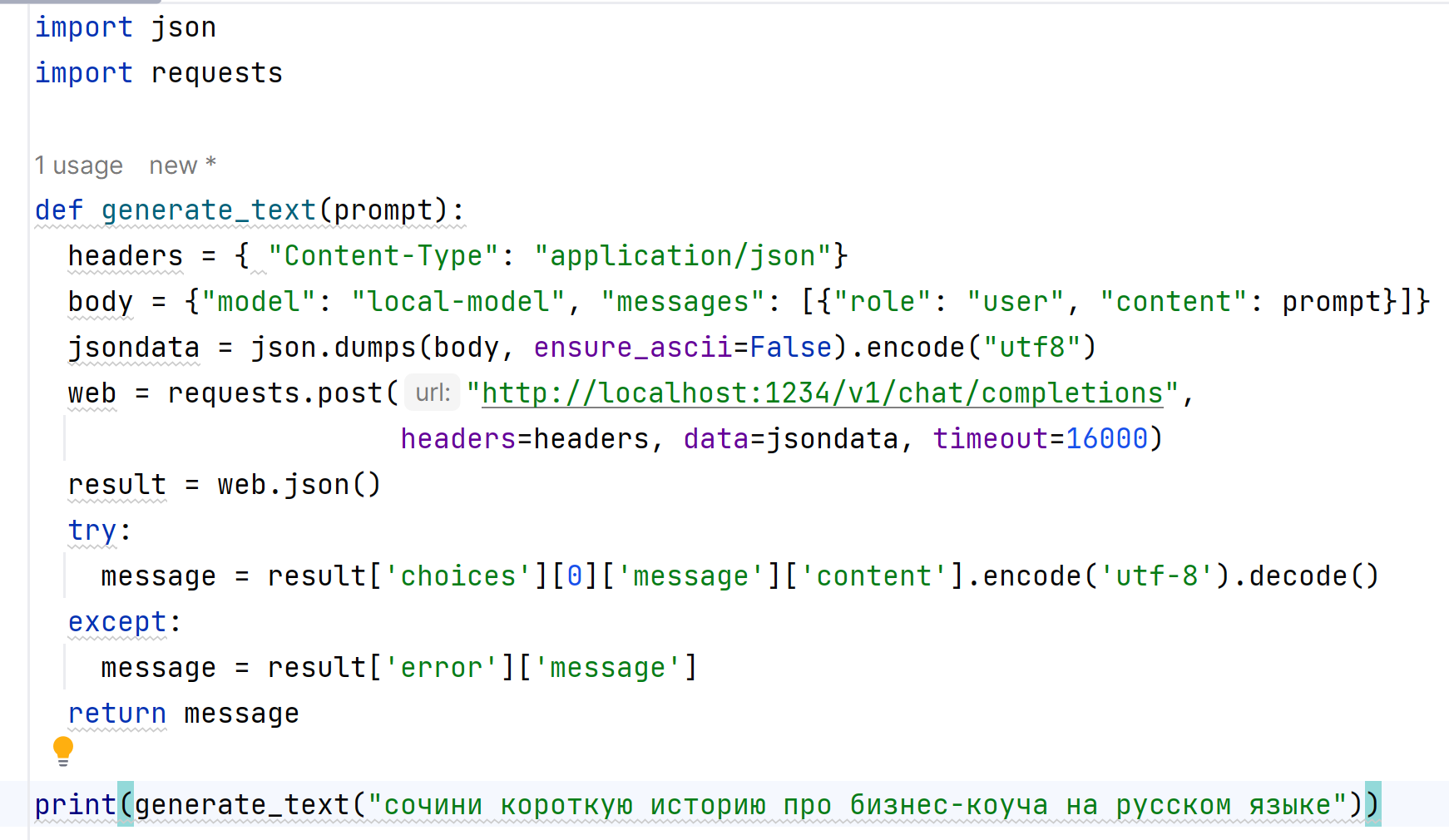
После запуска программы сервер начал генерировать историю (правда почему-то снова на английском):

Аналогичный запрос я реализовал для Excel, поэтому если у вас нет PyCharm или чего-то подобного - можно отправлять его обычной функцией из Power Query в Excel. Тут он уже ответил на русском и поинтереснее:
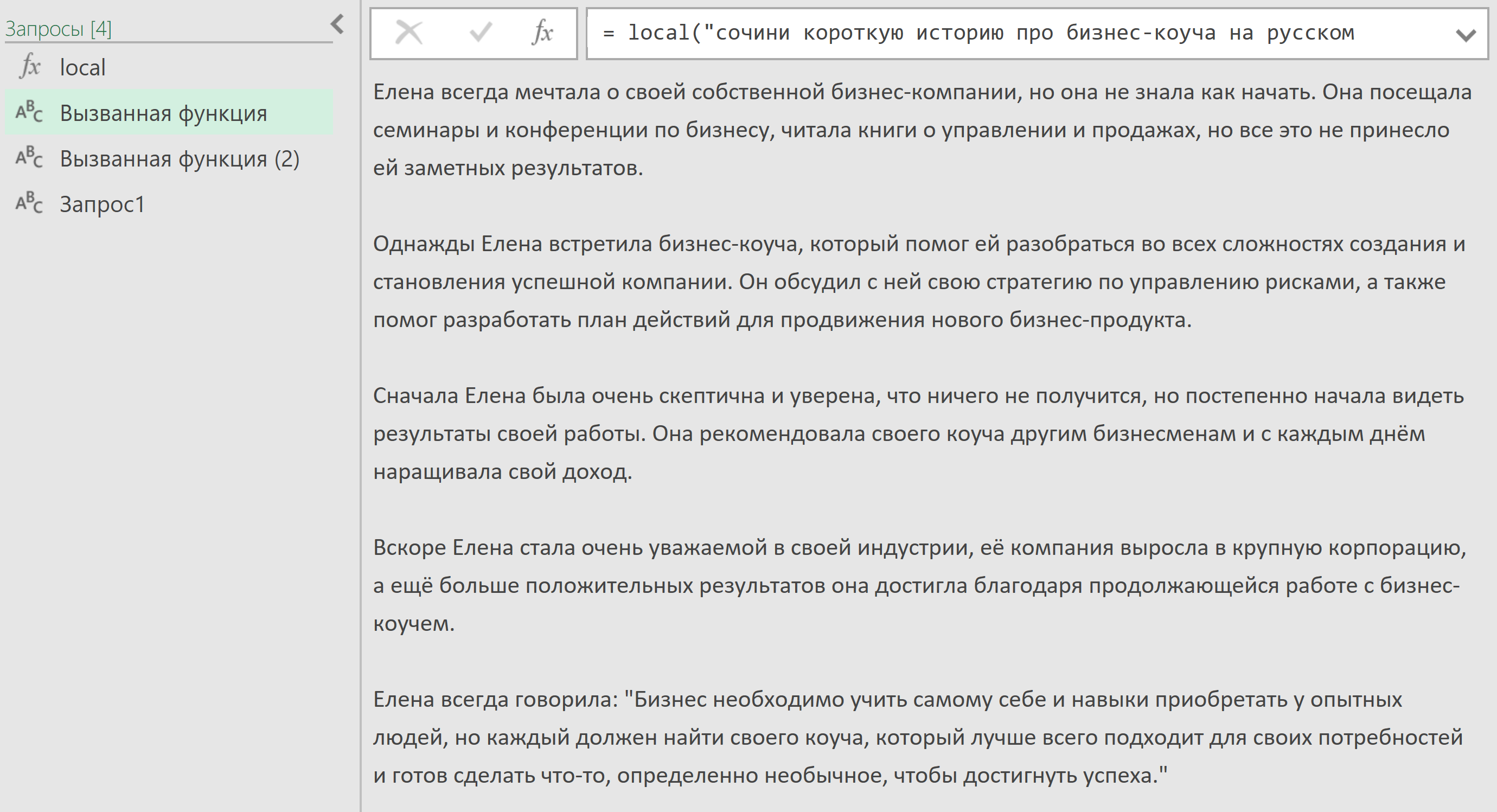
Оба скрипта я бесплатно опубликовал на Boosty вместе с маленькой инструкцией по их использованию.
Итоги работы с LM Studio
Какие выводы я сделал из экспериментов с локальными большими языковыми моделями?
- Локальные LLM могут писать достаточно неплохо, с небольшими ошибками, но при масштабировании этот минус будет сильно мешать.
- Для качественной работы локальных LLM нужен мощный компьютер - как по оперативке, так и в плане процессора.
- В идеале - запускать большие языковые модели на специальном сервере, который может расширять свои параметры (ядра процессора и оперативку) в зависимости от нагрузки.
- На текущий момент эффективнее работать с ChatGPT или другими сервисами по API, чем использовать локальные LLM на своём домашнем компьютере. Ответы получаются более качественные и меньше вероятность ошибки.
Вариант с арендой мощных серверов под запуск LLM я пока не тестировал, обязательно дополню данную статью если появятся интересные наблюдения. Но вариант с машиной, которая может автоматически задействовать больше ресурсов при большой нагрузке - довольно интересен. Он исключает проблемы, которые возникали у нас с моделями на Q8.
На текущий момент решения от крупных компаний типа OpenAI или Google - более интересны и дают более точные ответы, поэтому в работе планирую использовать их. Возможно, в будущем локальные модели также покажут свою эффективность и каждый из нас сможет иметь свой карманный ИИ 😊






Комментарии