

Все пользуются нейросетями, но к сожалению для многих ChatGPT - это говорящая энциклопедия. Он знает всё, но это общие знания, которые не имеют отношения к вам.
Можно ли обучить его, чтобы он разбирался в вашем продукте или давал персональные рекомендации клиентам? Это вполне реально, но нужно добавить в модель свои данные.
Дообучение (или Fine-Tuning) позволяет ChatGPT давать персонализированные ответы. Вы можете создать чат-бота, который будет консультировать клиентов по вашему продукту, или помощника, который даёт персональные советы.
Fine-Tuning можно разбить на 2 основных этапа:
- Подготовка и загрузка дообучающего файла
- Подбор параметров и отправка задачи на дообучение
Останется убедиться, что дообучение прошло успешно и начать пользоваться дообученной моделью, в которую можно по необходимости добавлять новые знания.
Не забывайте, что дообучение стоит денег, как и дальнейшее использование модели по API. Цены на дообучение и использование моделей можно посмотреть тут.
Напомню, что для доступа к ChatGPT в России приходится использовать VPN - как для работы с интерфейсом, так и по API.
Fine-Tuning в интерфейсе ChatGPT
Самый очевидный способ дообучить модель — воспользоваться интерфейсом ChatGPT. Вы загружаете свои данные и модель начинает давать точные релевантные ответы.
Переходим по ссылке и нажимаем "Create":
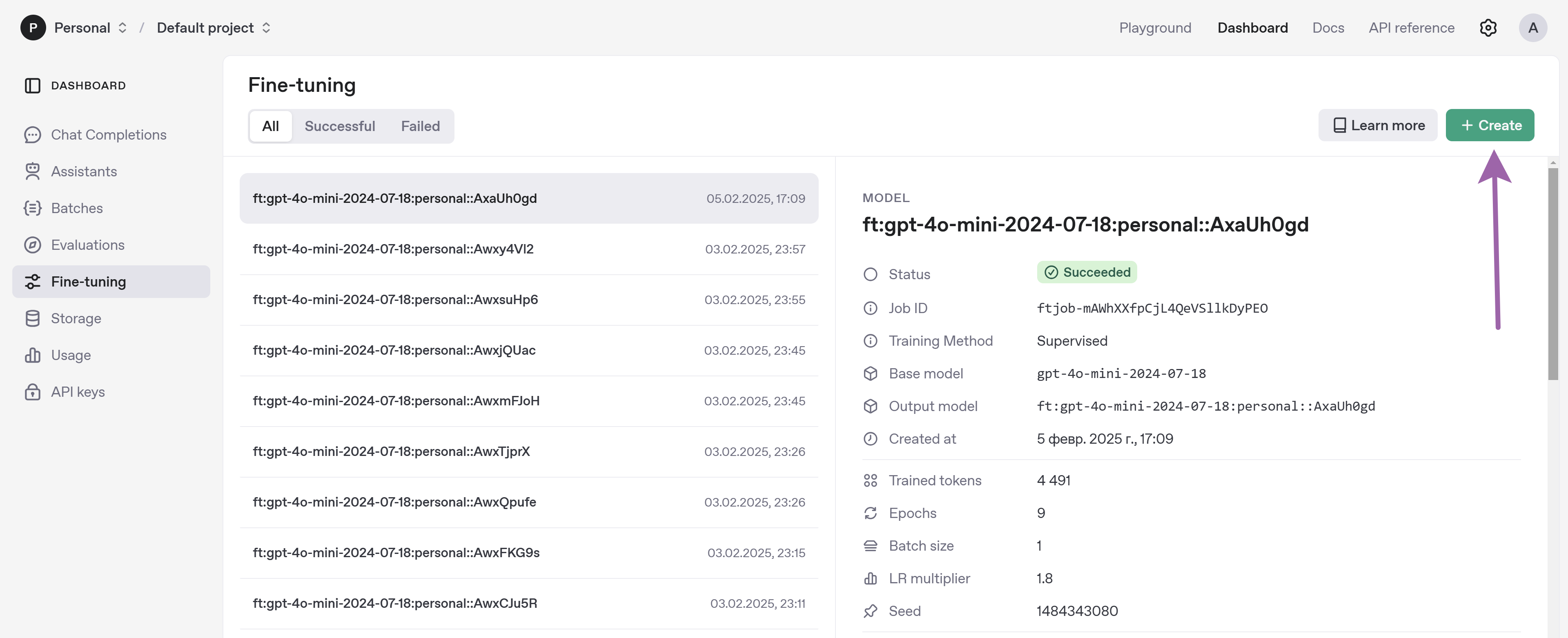
Открывается окно детальных настроек, в которых легко запутаться:
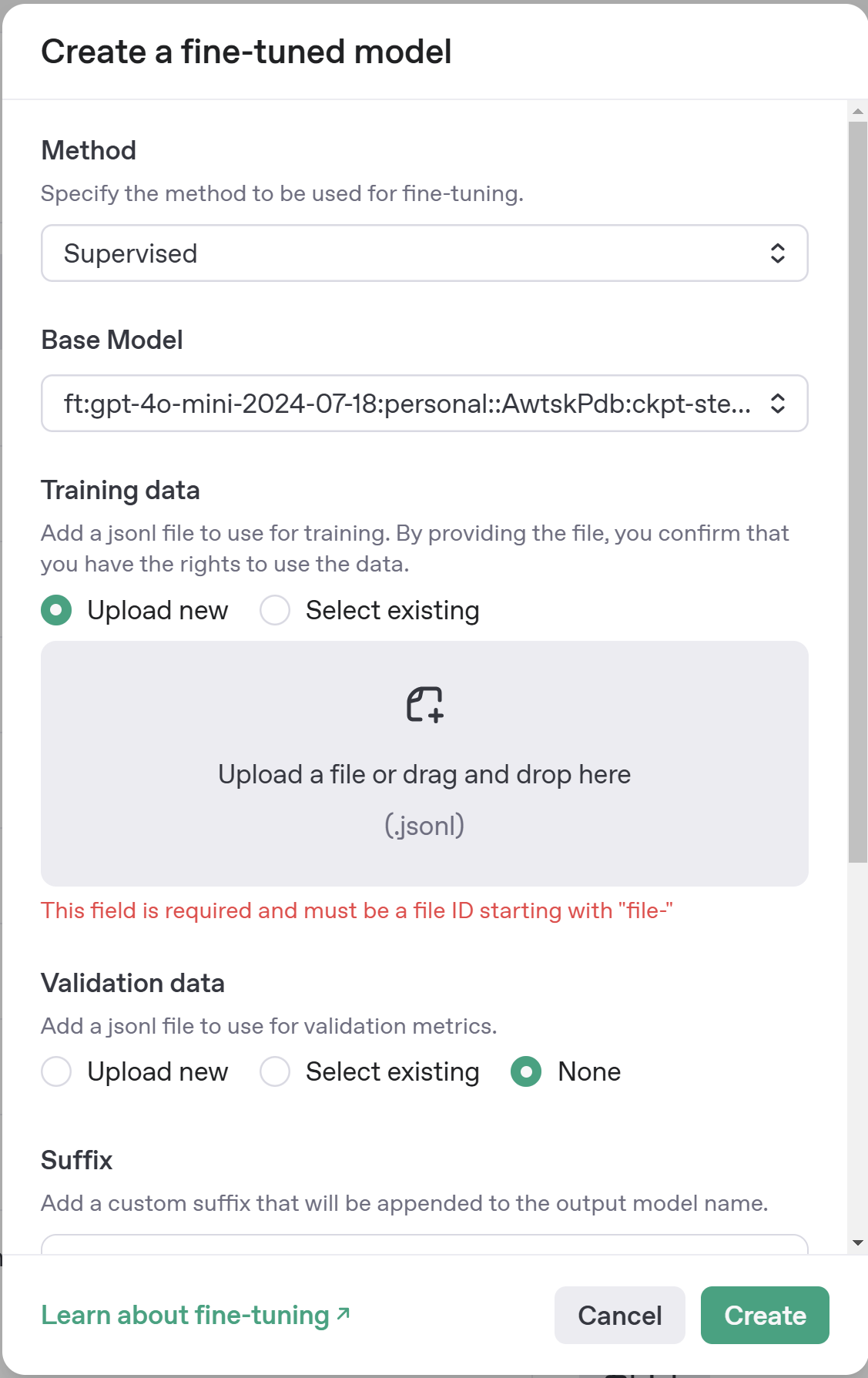
После указания настроек жмём "Create" и через какое-то время видим дообученную модель в списке Fine-Tuning. Давайте разберёмся в настройках😊
Экскурс по настройкам дообучения ChatGPT
1. Методы fine-tuning: Supervised vs. DPO (Direct Preference Optimization)
Есть два популярных метода:
- Supervised fine-tuning (обучение с учителем). Вы загружаете примеры, где есть вопрос и правильный ответ, и модель "понимает", как надо отвечать в таких ситуациях.
- DPO (Direct Preference Optimization, оптимизация по предпочтениям). Вы загружаете данные, где у одного запроса есть два ответа — один хороший, другой плохой. Модель учится выбирать лучший вариант. Модель учится отличать лучшее от худшего, даже если видит новый контекст.
На текущий момент выбор моделей для DPO сильно ограничен. В том числе для DPO недоступны ранее дообученные модели по методу Supervised.
2. Выбор модели для дообучения Base Model
Вариант 1: выбрать одну из популярных моделей и дообучить её.
Вариант 2: дообучить уже дообученную модель.
Если вы уже дообучили модель, можно снова её дообучить на новых данных, но есть нюансы:
3. Training Data
ChatGPT требует отправки дообучающих данных в формате jsonl. Это похоже на обычный json, но является набором строк, каждая из которых представляет собой небольшой словарь. Для наглядности я добавил переносы, но если если присмотреться, в моём файле всего 3 строки (метод дообучения Supervised):
{"messages": [
{"role": "system", "content": "Ты - саркастический чат-бот, который отвечает по фактам."},
{"role": "user", "content": "Назови столицу Таиланда?"},
{"role": "assistant", "content": "Крунг Тхеп Маханакхон Амон Раттанакосин Махинтараюттхая Махадилок Пхоп Ноппарат Ратчатхани Буриром Удомратчанивет Махасатан Амон Пиман Аватан Сатит Саккатхаттийя Витсанукам Прасит."}
]}
{"messages": [
{"role": "system", "content": "Ты - саркастический чат-бот, который отвечает по фактам."},
{"role": "user", "content": "Кто написал преступление и наказание?"},
{"role": "assistant", "content": "Достоевский, ты вообще знаком с классикой?"}
]}
{"messages": [
{"role": "system", "content": "Ты - саркастический чат-бот, который отвечает по фактам."},
{"role": "user", "content": "Сколько глубина марианской впадины?"},
{"role": "assistant", "content": "10994 метров, ты решил поплавать?"}
]}В каждом обучающем сообщении может быть 3 роли - system (общая поведенческая инструкция), user (реплика пользователя) и assistant (ответ ассистента). Если поведенческой инструкции нет, её можно оставить пустой.
Если вы делаете дообучение по модели DPO, структура обучающих данных будет чуть сложнее. Всё делится на input - поступающую от пользователя информацию и 2 вида output - то, что должен или не должен ответить наш помощник. preferred_output - предпочитаемый ответ, non_preferred_output - так отвечать не нужно. Каждая строка для DPO будет выглядеть так:
{
"input":
{"messages":
[
{"role": "system", "content": "Вы являетесь помощником-чатом. Пожалуйста, отвечайте на вопросы пользователя."},
{"role": "user", "content": "Что такое глобальное потепление?"}
]
},
"preferred_output":
[
{"role": "assistant", "content": "Глобальное потепление — это долгосрочное повышение средней температуры на Земле."}
],
"non_preferred_output":
[
{"role": "assistant", "content": "Глобальное потепление — это миф, не подтверждённый научными данными."}
]
}Формат для метода DPO более сложный, составлять обучающую выгрузку дольше, но результат должен получиться более качественный. На практике мне так и не удалось получить внятный ответ при обучении по этому методу, но возможно это получится у вас.
3. Validation data (валидационные данные)
Validation data — отдельный набор данных, на котором проверяют качество обучения. Ранее мы дали модели 1000 примеров для обучения, теперь мы даём ей новые 200 примеров, чтобы проверить качество ответов.
Важно убедиться, что модель не просто "зазубрила" данные, а реально поняла логику. Если этого не случилось, можно попробовать другие настройки дообучения.
4. Suffix (часть имени)
Suffix - это текст, который добавляется к названию модели, чтобы не путать её с другими. Например: chatbot_products или client_personal_help. Если вы обучаете несколько разных моделей, различать их будет гораздо проще.
5. Seed (параметр случайности)
Seed — это число, которое задаёт случайность при обучении. Если мы запускаем обучение два раза на одних и тех же данных, результаты могут быть разными из-за случайных факторов в процессе обучения. Но если поставить одинаковый seed, результат всегда будет одинаковым.
Это удобно для экспериментов, чтобы результаты можно было повторить. Указать можно любое число - например: 42, 1234, 7777. Если ничего не указать - GPT подберёт случайное число сам.
6. Batch size, Learning rate multiplier, Number of epochs
👉 Batch size (размер пакета)
Обучение идёт порциями, а не сразу на всех данных. Batch size – это кол-во примеров, которое модель обрабатывает за один шаг.
👉 Learning rate multiplier (скорость восприятия нового)
Этот коэффициент определяет насколько сильно модель обновляет свои знания при дообучении.
👉 Number of epochs (количество эпох)
Эпоха – это когда модель прошлась по всем твоим данным один раз.
Если эпох слишком мало – модель может недоучиться. Если слишком много – модель может переучиться и запоминать ошибки. Обычно выбирают 3-5 эпох.
Fine-Tuning с помощью API ChatGPT
Чем тут может помочь API? Дообучение через интерфейс выглядит простым, основная сложность - сбор обучающего файла.
Если вы - программист, собрать jsonl из простой таблички для вас несложно. Но у обычного пользователя это вызовет трудности. Собрать дообучающий файл в Excel и отправить по API в ChatGPT - гораздо проще, чем писать скрипт по созданию jsonl.
Еще один важный плюс дообучения по API - процесс может быть автоматизирован. Если к вам регулярно поступают удачные примеры "вопрос-ответ", довольно удобно отправлять их в качестве обучающих примеров автоматом.
Но если не говорить о полной автоматизации, мы можем использовать интерфейс как для загрузки файла, так и для выполнения дообучения. А можем что-то из этого делать по API, если так удобнее🙄
Отправка файлов в ChatGPT по API
Специально для удобной отправки дообучающих данных в ChatGPT у нас есть Excel-файл, который доступен на Boosty. Подробно про него рассказал в видео на YouTube. Файл работает по методу Supervised - этот метод более распространён, имеет простой формат файла и более широкий список моделей для дообучения.
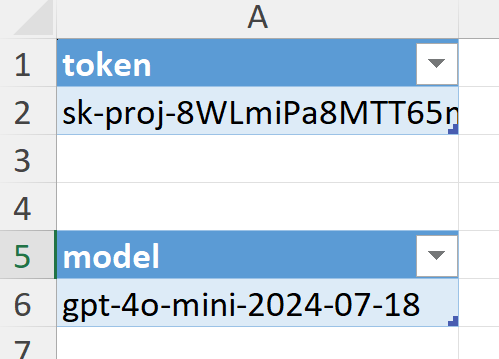
На первой вкладке можно задать свой токен ChatGPT и указать модель, которую вы хотите дообучить:
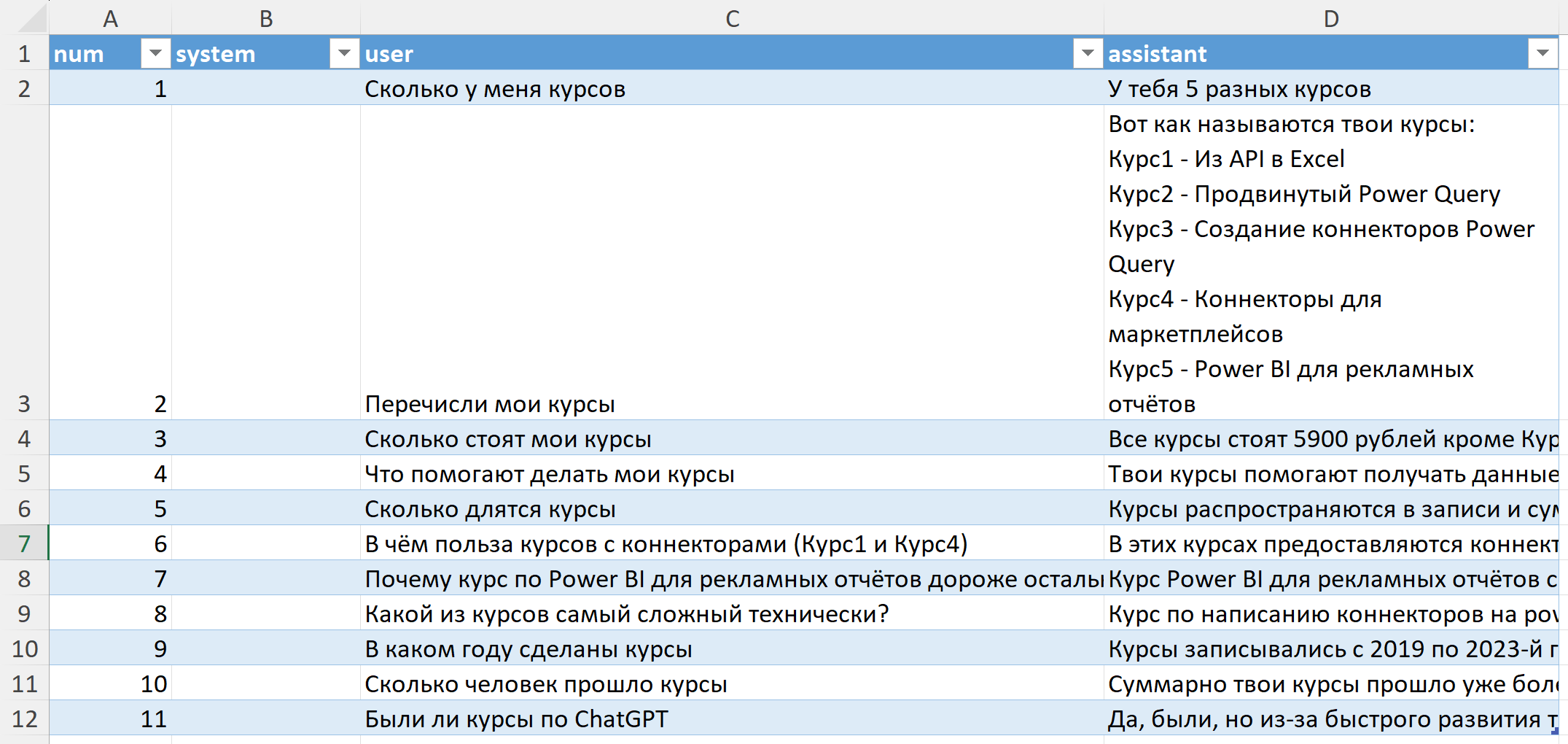
На вкладке "fine-tuning-table" заполняем дообучающую табличку - я буду отправлять в GPT информацию о своих курсах:
После заполнения таблички нужно создать jsonl-файл. Переходим на следующую вкладку "jsonFile", жмём правой кнопкой на зелёную таблицу и выбираем "обновить":
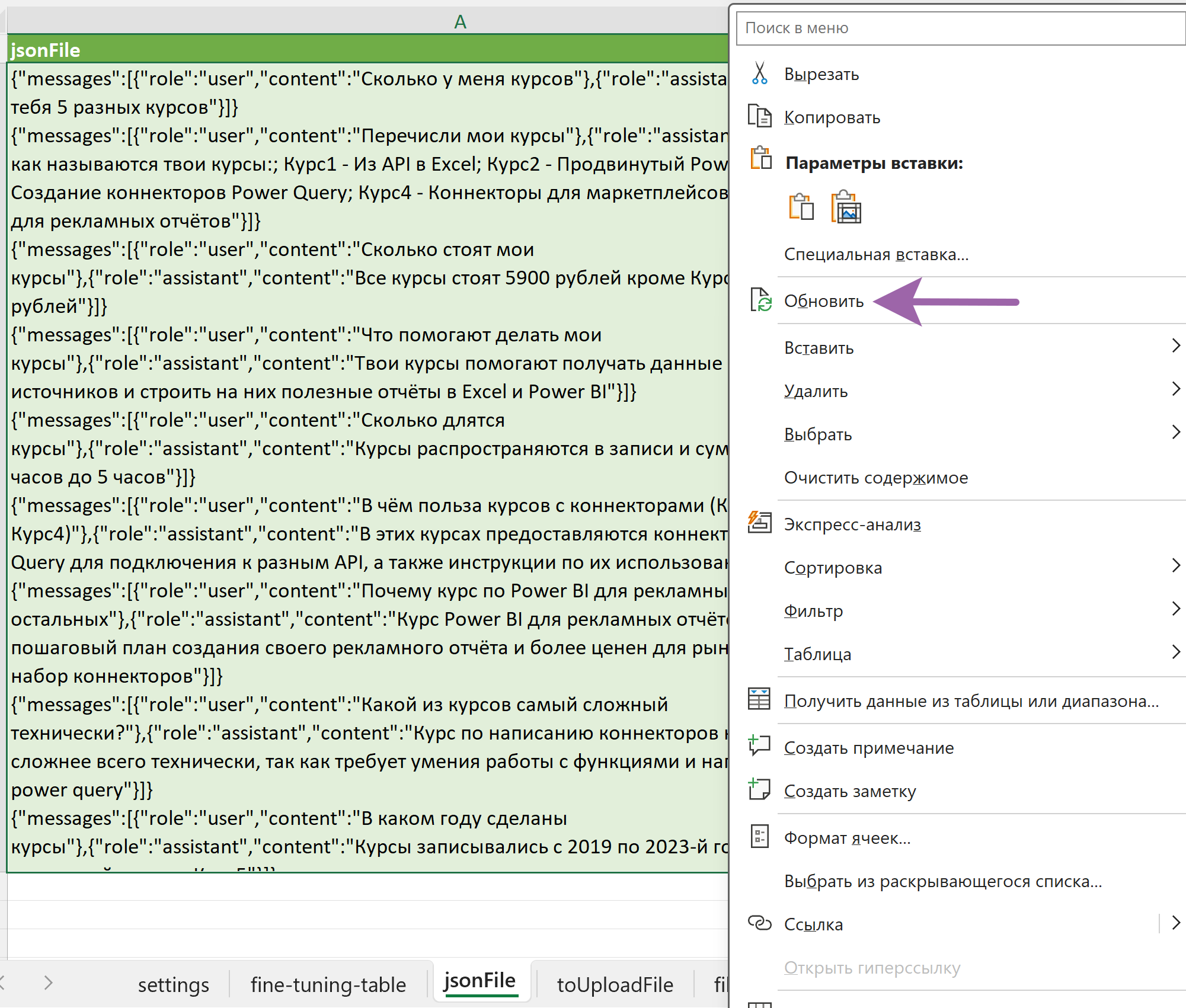
Данные из таблицы подтянулись и jsonl готов к отправке. На вкладке "toUploadFile" задаём название файла для загрузки, находим запрос с таким же названием и выбираем "Обновить" - наш файл грузится в ChatGPT:
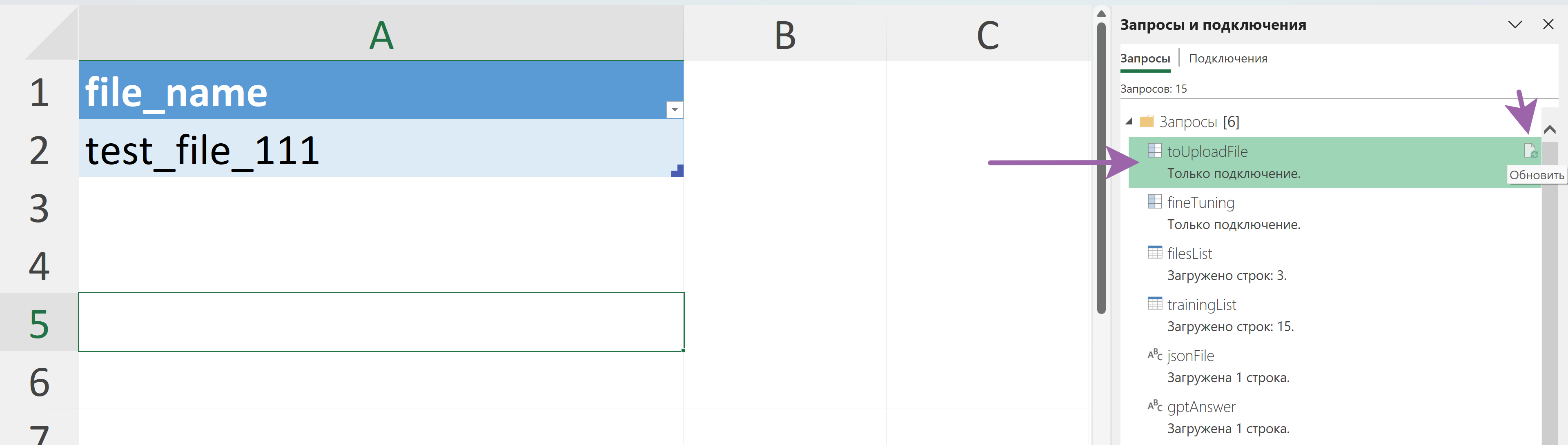
Файл успешно загружен и теперь его можно использовать для Fine-Tuning в ChatGPT. Дообучение можно запустить как из интерфейса, так и по API, разница лишь в параметрах.
Дообучение модели ChatGPT по API
Если вам требуется дообучать модель, указывая свои параметры - лучше делать это через интерфейс ChatGPT, так как в файле нет подобных настроек. Если же дообучение с параметрами по умолчанию вас устраивает - продолжайте работать через файл.
На вкладке "fileList" обновляем таблицу, где видим наш файл в списке загруженных файлов:
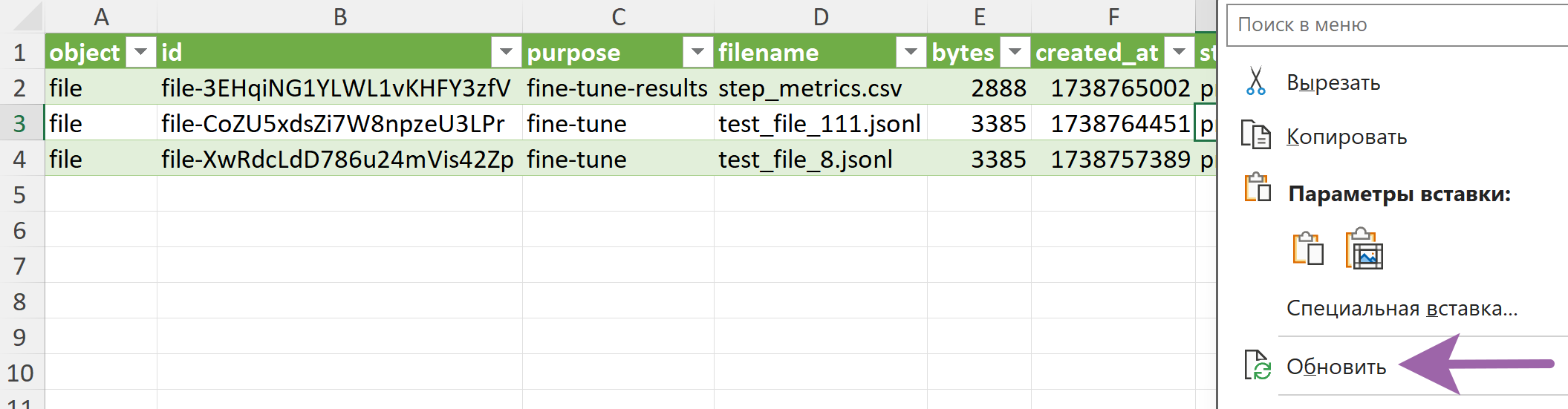
Копируем ID файла и вставляем на вкладку "fineTuning", а затем создаём запрос на дообучение, обновляя справа запрос "fineTuning".
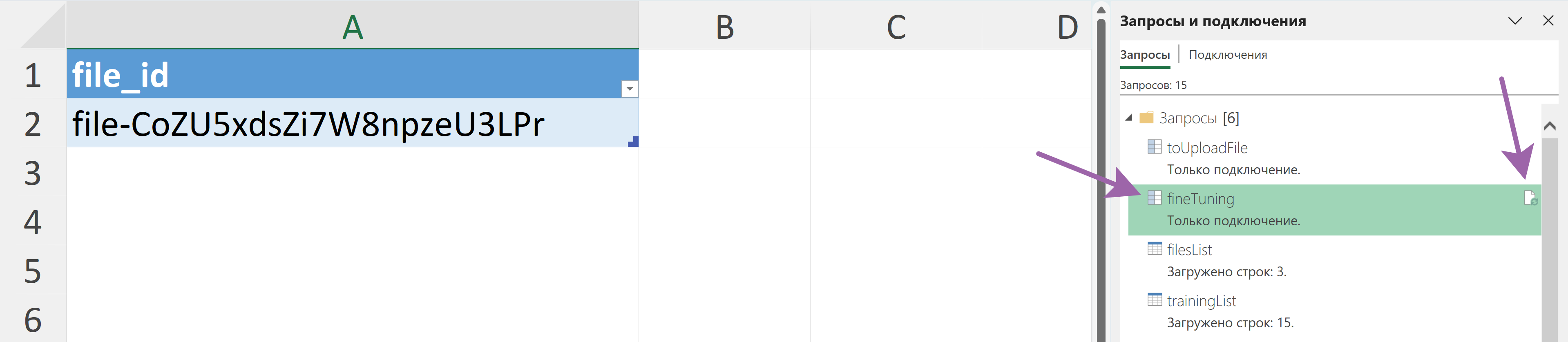
И на вкладке "trainingList" видим список Fine-Tuning и их статусы:
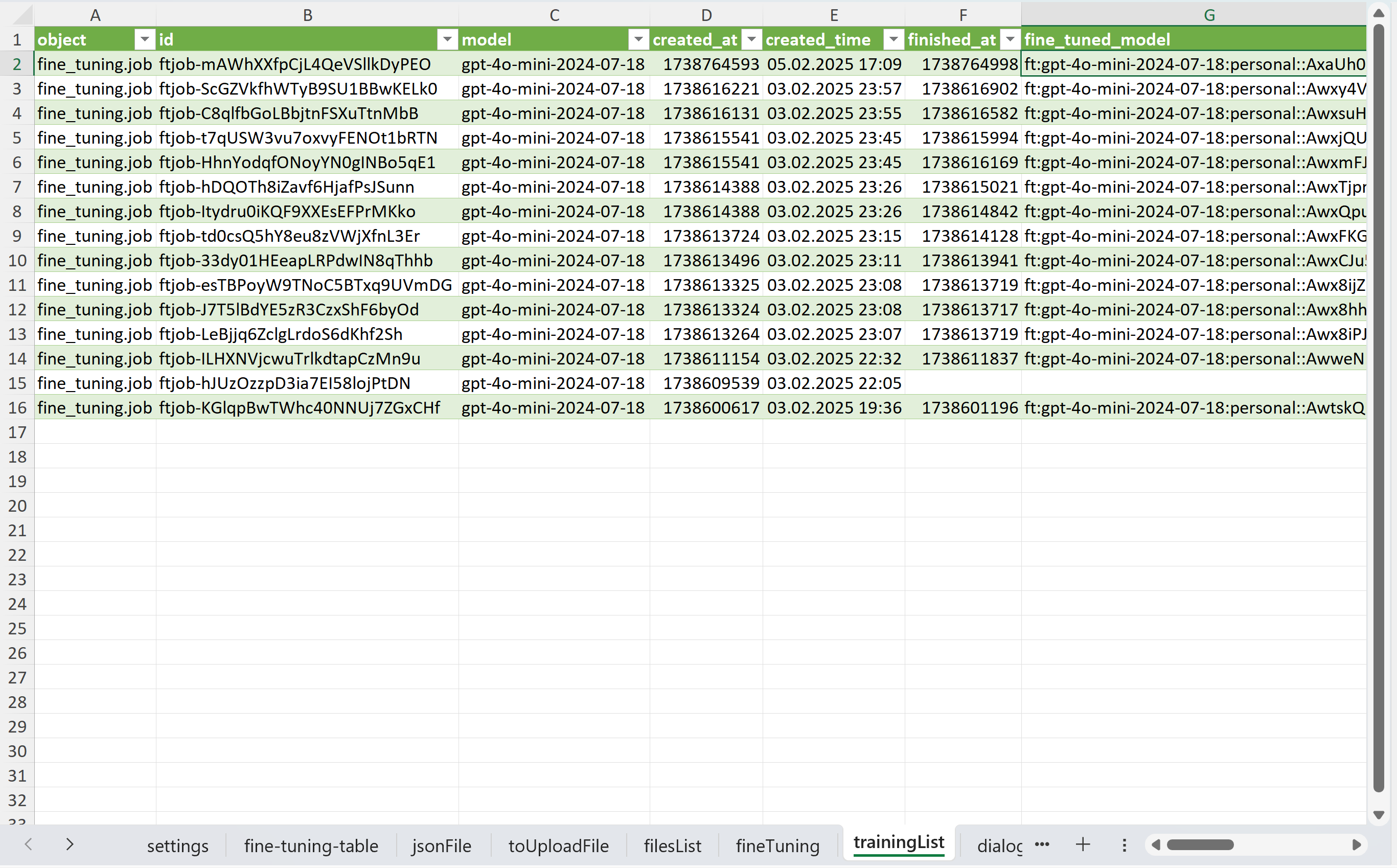
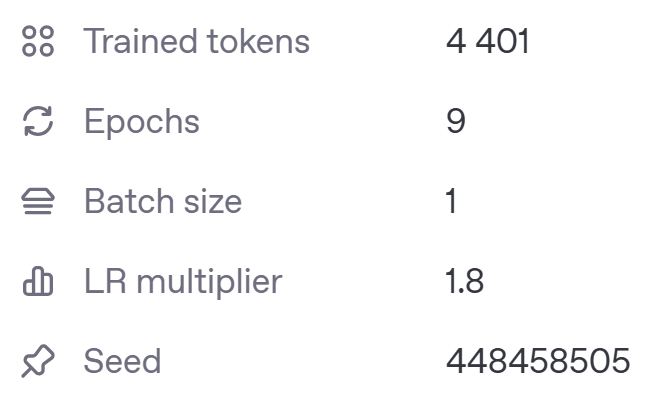
После завершения дообучения в интерфейсе отобразились параметры, которые были подобраны по умолчанию. Степень запоминания (LR multiplier) крайне высокая, возможно потому, что я отправлял всего 10 строк:
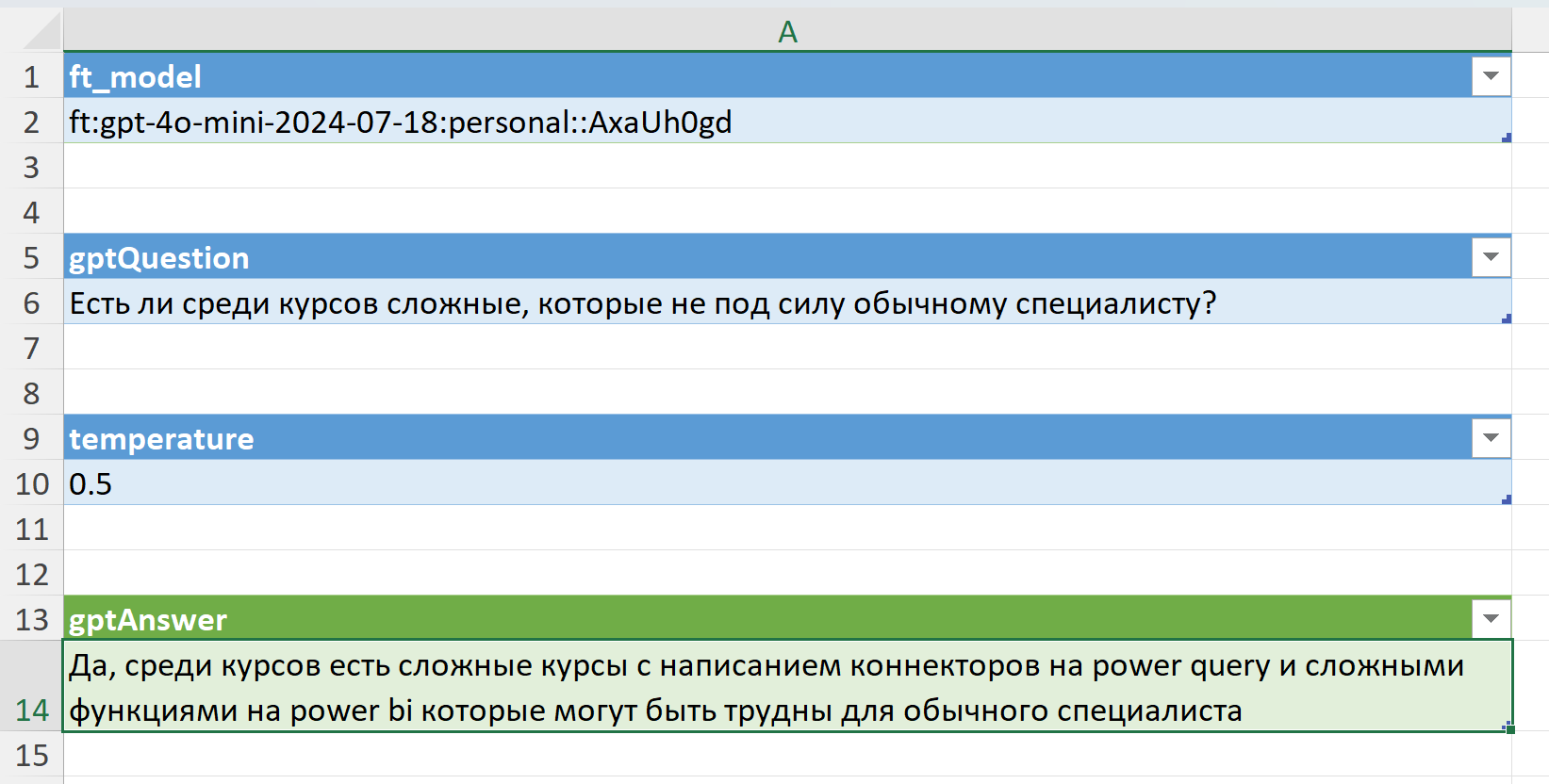
Для тестирования fine-tuned моделей есть вкладка dialogue, где можно указать модель, задать ей вопрос и настроить температуру. Для получения ответа обновите табличку gptAnswer:
Я оставил настройки по умолчанию и дообучал ChatGPT с ними. Но вы можете выставить свои настройки в интерфейсе либо написать свой скрипт по дообучению.
Итоги и советы
Fine-Tuning в ChatGPT - замечательная возможность сделать персонального ассистента. Дообучение модели состоит из 2 этапов - работа с дообучающим файлом и работа по дообучению модели. Оба этапа Fine-Tuning можно выполнять как через интерфейс ChatGPT, так и по API.
Для удобства я рекомендую готовить дообучающий файл через Excel и отправлять прямо из Excel с помощью API. Если вы хотите добавить свои настройки дообучения, дальнейшее дообучение можно делать через интерфейс. Если же вас устраивают настройки по умолчанию - можно выполнять дообучение также в Excel-файле.
Что можно посоветовать по содержанию обучающего файла:
- Добавляйте больше примеров. Обычно обучение начинается с 1000 строк, а лучше отправить от 10 000 строк до 100 000 строк чтобы модель лучше усвоила знания.
- Добавляйте разнообразные примеры, избегая однотипных формулировок и шаблонных фраз – модель может заучить однотипные ответы и выдавать их везде.
- Тестируйте модель на примерах, которых не было в обучающих данных, чтобы проверить насколько хорошо она усвоила предоставленные знания.
Когда модель дообучена и успешно работает, можно использовать её в любой программе на любом языке программирования.
Не забывайте следить за расходом средств, ведь работа по API, как и дообучение моделей является платным🤑
